ESQUEMAS DE FRAGMENTACION DE UNA BASE DE DATOS DISTRIBUIDA
El problema de fragmentación se
refiere al particionamiento de la información para
distribuir cada parte a los diferentes sitios de la
red
Objetivos de la fragmentación
El objetivo de la fragmentación consiste
en dividir la relación en un conjunto de relaciones
más pequeñas tal que algunas de las aplicaciones de
usuario sólo hagan uso de un fragmento.
Sobre este marco, una fragmentación óptima
es aquella que produce un esquema de división que minimiza
el tiempo de ejecución de las aplicaciones que emplean
esos fragmentos.
La unidad de fragmentación ideal no es la tabla
sino una subdivisión de ésta.
Esto es debido a:
-
Las aplicaciones usan vistas definidas sobre varias
relaciones, es decir, se forman a partir de "trozos" de
varias tablas. Si conseguimos que cada una de las vistas
esté definida sobre subtablas locales (o en su defecto
lo mas "cerca" posible) a cada aplicación, es de
esperar un incremento en el rendimiento.
-
Si múltiples vistas de diferentes
aplicaciones están definidas sobre una tabla no
fragmentada, se tiene :
-
Si la tabla no está replicada entonces se
produce generación de tráfico por accesos
remotos.
-
Si la tabla está replicada en todos o algunos de los sitios donde residen cada una de las aplicaciones entonces la generación de trafico innecesario es producida por la necesidad de la actualización de las copias.
Ventajas
Al descomponer una relación en fragmentos (unidades de distribución) :-
Permitimos el procesamiento concurrente de
transacciones ya que no se bloquean tablas enteras sino
subtablas, por lo que dos consultas pueden acceder a la misma
tabla a fragmentos distintos.
-
Permitimos la paralelización de consultas al
poder descomponerlas en subconsultas, cada una de la cuales
trabajará con un fragmento diferente
incrementándose así el rendimiento.
Desventajas
-
Degradación del rendimiento en vistas
definidas sobre varios fragmentos ubicados en sitios
distintos (es necesario realizar operaciones con esos trozos
lo cual es costoso)
-
El control semántico se dificulta y el
rendimiento se degrada debido que la verificación de
restricciones de integridad (claves ajenas, uniques, etc)
implican buscar fragmentos en múltiples
localizaciones.
Tipos de fragmentación de datos
Existen tres tipos de fragmentación:-
Fragmentación horizontal
-
Fragmentación vertical
-
Fragmentación híbrida
-
Condición de completitud.
-
Condición de
Reconstrucción.
-
Condición de Fragmentos Disjuntos.
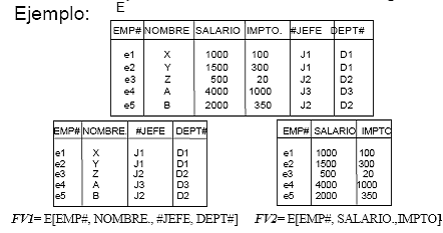
FRAGMENTACION VERTICAL DE UNA BASE DE DATOS DISTRIBUIDA
FRAGMENTACION HORIZONTAL DE UNA BASE DE DATOS DISTRIBUIDA
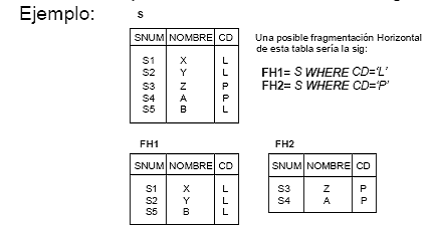
La fragmentación horizontal de una
relación R produce una serie de fragmentos
R1, R2, ..., Rr, cada uno de los cuales contiene un
subconjunto de las tuplas de R que cumplen determinadas
propiedades (predicados)
Fragmentación horizontal primaria y derivada
La Fragmentación Horizontal Primaria
(FHP) de una relación se obtiene usando predicados
que están definidos en esa relación.
La Fragmentación Horizontal Derivada
(FHD) por otra parte, es el particionamiento de una
relación como resultado de predicados que se definen en
otra relación.
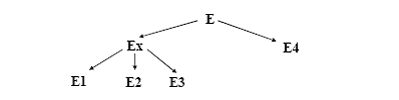
FRAGMENTACION MIXTA DE UNA BASE DE DATOS DISTRIBUIDA
Consiste en aplicar las operaciones de fragmentación vistas anteriormente de manera recursiva, satisfaciendo las
condiciones de correctés cada vez que se
realiza la fragmentación.
La reconstrucción puede ser obtenida
aplicando las reglas de reconstrucción en
orden inverso.
De esta forma podemos fragmentar nuestra tabla global en los pedazos que queramos y como queramos.
Ejemplo: Considere la relación de empleado (E).
Una posible fragmentación híbrida sería:
De esta forma podemos fragmentar nuestra tabla global en los pedazos que queramos y como queramos.
Ejemplo: Considere la relación de empleado (E).
Una posible fragmentación híbrida sería:
SOFTWARE UTILIZADO EN UNA BASE DE DATOS DISTRIBUIDA
Sistema manipulador de base de datos distribuida (DDBMS)
Este sistema está formado por las transacciones y los administradores
de la base de datos distribuidos. Un DDBMS implica un conjunto de
programas que operan en diversas computadoras, estos programas pueden
ser subsistemas de un único DDBMS de un fabricante o podría consistir de
una colección de programas de diferentes fuentes.
Administrador de transacciones distribuidas (DTM)
Este es un programa que recibe las solicitudes de procesamiento de
los programas de consulta o transacciones y las traduce en acciones para
los administradores de la base de datos. Los DTM se encargan de
coordinar y controlar estas acciones. Este DTM puede ser propietario o
libre.
Sistema manipulador de base de datos (DBMS)
Es un programa que procesa cierta porción de la base de datos
distribuida. Se encarga de recuperar y actualizar datos del usuario y
generales de acuerdo con los comandos recibidos de los DTM.
Nodo
Un nodo es una computadora que ejecuta un DTM o un DBM o ambos. Un
nodo de transacción ejecuta un DTM y un nodo de base de datos ejecuta un
DBM.


